RNN vs. Dense neural networks for time-series
June 27, 2018
R modellingThis is a continuation from my last post comparing an automatic neural network from the package forecast with a manual Keras model.
I used a fully connected deep neural network in that post to model sunspots. There’s another type of model, called a recurrent neural network, that has been widely considered to be excellent at time-series predictions. We’ll use the Gated Recurrent Units (GRU) model specifically. Let’s run through a comparison between a deep feed-forward neural network model established in the prior post with a GRU type of model.
Dataset
We’ll reuse the sunspots dataset since it’s one of the better ones (it’s long and exhibits nice seasonal patterns).
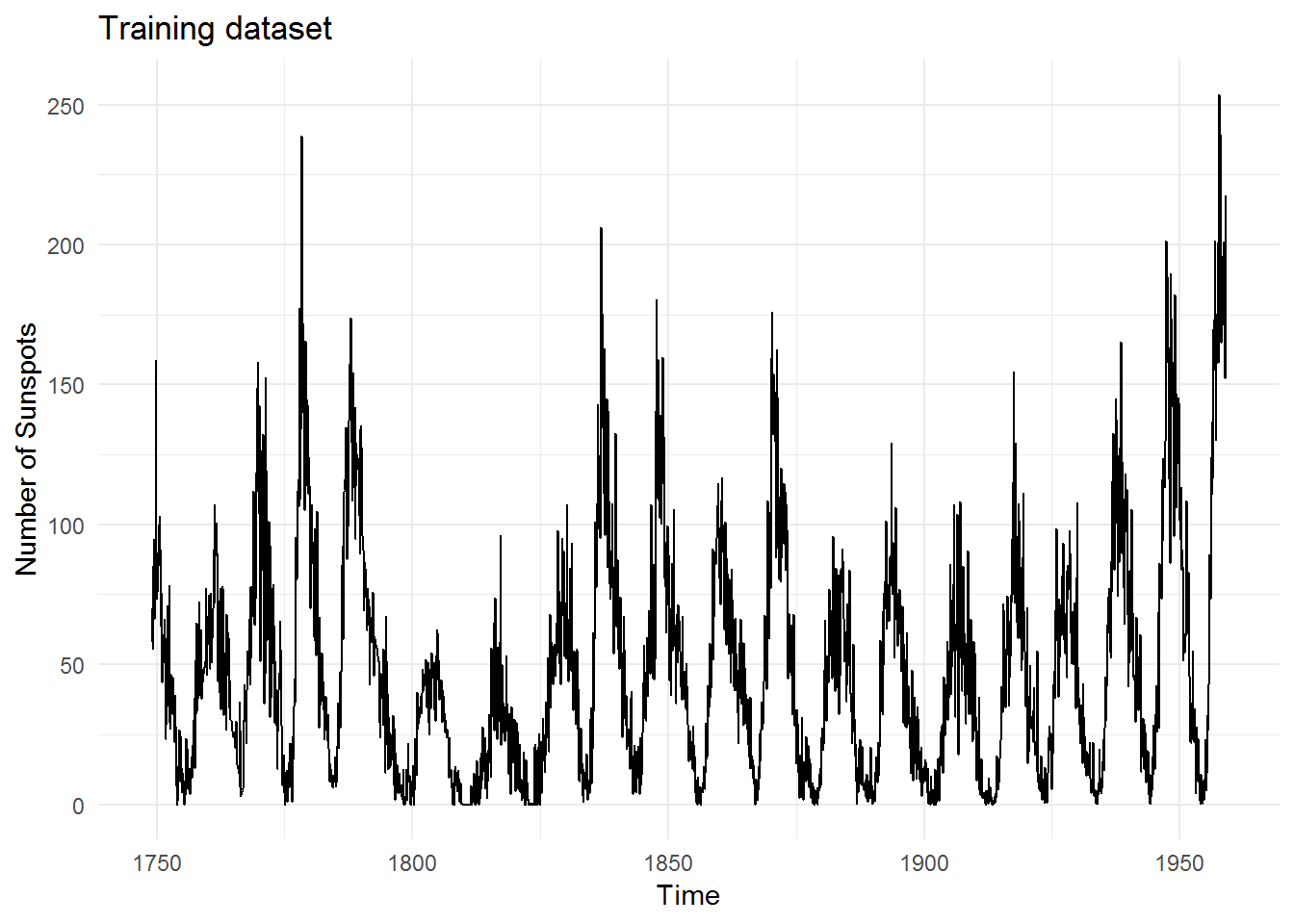
And this is the testing data which we will test our models against:
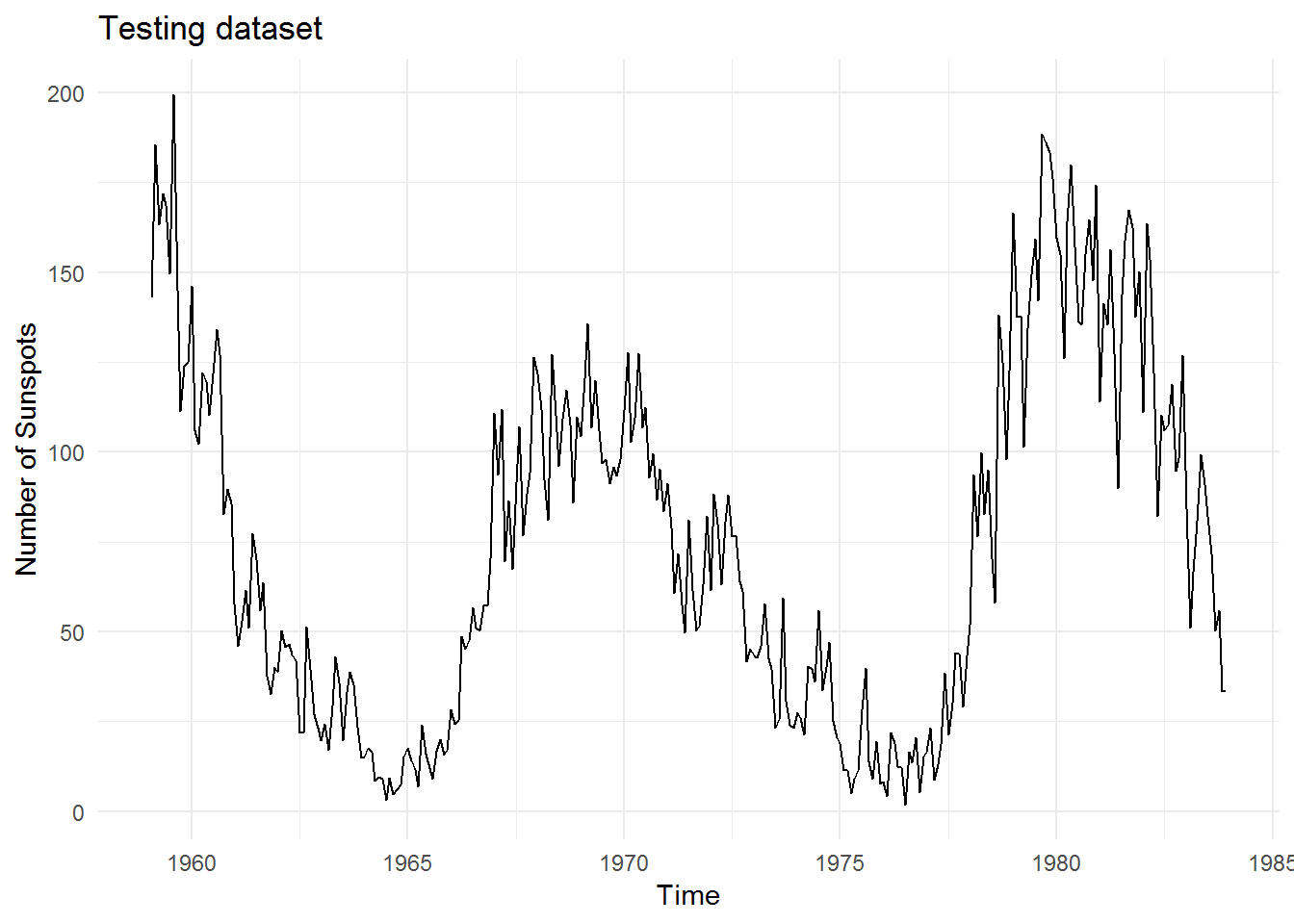
Dense layers
First up is the dense network. I’m going to skip showing the code for this here since I showed it in my last post.
Here are the model details:
## Model
## ___________________________________________________________________________
## Layer (type) Output Shape Param #
## ===========================================================================
## dense_1 (Dense) (1, 256) 37120
## ___________________________________________________________________________
## dense_2 (Dense) (1, 128) 32896
## ___________________________________________________________________________
## dense_3 (Dense) (1, 32) 4128
## ___________________________________________________________________________
## dense_4 (Dense) (1, 1) 33
## ===========================================================================
## Total params: 74,177
## Trainable params: 74,177
## Non-trainable params: 0
## ___________________________________________________________________________GRU
Step 1 - we need to slightly tweak the data for GRU models since GRU expects a 3D tensor, instead of the 2D tensor used in the prior model.
Step 2 - we can now construct a GRU model:
# Model params
units <- 4
inputs <- 1
# Create model
model.GRU <- keras_model_sequential()
model.GRU %>%
layer_cudnn_gru(units = units,
input_shape = c(lookback, 1),
batch_size = inputs,
stateful = T,
return_sequences = T
) %>%
layer_dropout(0.2) %>%
layer_cudnn_gru(units = units/2,
stateful = T,
return_sequences = T) %>%
layer_cudnn_gru(units = 1,
stateful = T) %>%
layer_dropout(0.2) %>%
layer_dense(units = 1)
# Compile model
model.GRU %>% compile(optimizer = "rmsprop",
loss = "mean_squared_error",
metrics = "mae")Step 3 - we can now attempt to train the model:
## Model
## ___________________________________________________________________________
## Layer (type) Output Shape Param #
## ===========================================================================
## cu_dnngru_1 (CuDNNGRU) (1, 144, 4) 84
## ___________________________________________________________________________
## dropout_1 (Dropout) (1, 144, 4) 0
## ___________________________________________________________________________
## cu_dnngru_2 (CuDNNGRU) (1, 144, 2) 48
## ___________________________________________________________________________
## cu_dnngru_3 (CuDNNGRU) (1, 1) 15
## ___________________________________________________________________________
## dropout_2 (Dropout) (1, 1) 0
## ___________________________________________________________________________
## dense_5 (Dense) (1, 1) 2
## ===========================================================================
## Total params: 149
## Trainable params: 149
## Non-trainable params: 0
## ___________________________________________________________________________Step 4 - we can now make predictions from the model:
## Predict based on last observed sunspot number
predictions.GRU <- numeric() #vector to hold predictions.GRU
# Generate predictions.GRU, starting with last observed sunspot number and feeding
# new predictions.GRU back into itself
for(i in 1:n){
pred.y.GRU <- x.GRU[(nrow(x.GRU) - inputs + 1):nrow(x.GRU), 1:lookback, 1]
dim(pred.y.GRU) <- c(inputs, lookback, 1)
# forecast
fcst.y.GRU <- model.GRU %>% predict(pred.y.GRU, batch_size = inputs)
fcst.y.GRU <- as_tibble(fcst.y.GRU)
names(fcst.y.GRU) <- "x"
# Add to previous dataset data.tibble.rec
data.tibble.rec.GRU <- rbind(data.tibble.rec.GRU, fcst.y.GRU)
## Recalc lag matrix.GRU
# Setup a lagged matrix.GRU (using helper function from nnfor)
data.tibble.rec.lag <- nnfor::lagmatrix(data.tibble.rec.GRU$x, 0:lookback)
colnames(data.tibble.rec.lag) <- paste0("x-", 0:lookback)
data.tibble.rec.lag <- as_tibble(data.tibble.rec.lag) %>%
filter(!is.na(.[, ncol(.)])) %>%
as.matrix()
# x.GRU is input (lag), y.GRU is output, multiple inputs
x.GRU <- data.tibble.rec.lag[, 2:(lookback + 1)]
dim(x.GRU) <- c(nrow(x.GRU), ncol(x.GRU), 1)
y.GRU <- data.tibble.rec.lag[, 1]
dim(y.GRU) <- length(y.GRU)
# Invert recipes
fcst.y.GRU <- fcst.y.GRU * (range.max.step - range.min.step) + range.min.step
# save prediction
predictions.GRU[i] <- fcst.y.GRU %>%
InvBoxCox(l)
predictions.GRU <- unlist(predictions.GRU)
}Results!
Ok let’s see some results! (Since we have 2 models, I’m also going to sneak in an ensemble model which is simply an average of the dense and GRU model predictions).